
Wisdom O. Ikezogwo
PhD Candidate, Computer Science & Engineering, University of Washington
I am a final-year PhD student at the Paul G. Allen School of Computer Science & Engineering at the University of Washington, advised by Prof. Ranjay Krishna and Prof. Linda Shapiro. I am also a student researcher at the PRIOR team at AI2. Previously, I received my B.Sc. from Obafemi Awolowo University, where I worked with Prof. Kayode P. Ayodele.
My research advances multimodal representation and generative modeling through effective alignment strategies, spanning large-scale data curation, benchmarking, multi-agent reasoning, and AI for Science with an emphasis on medical sciences.
News
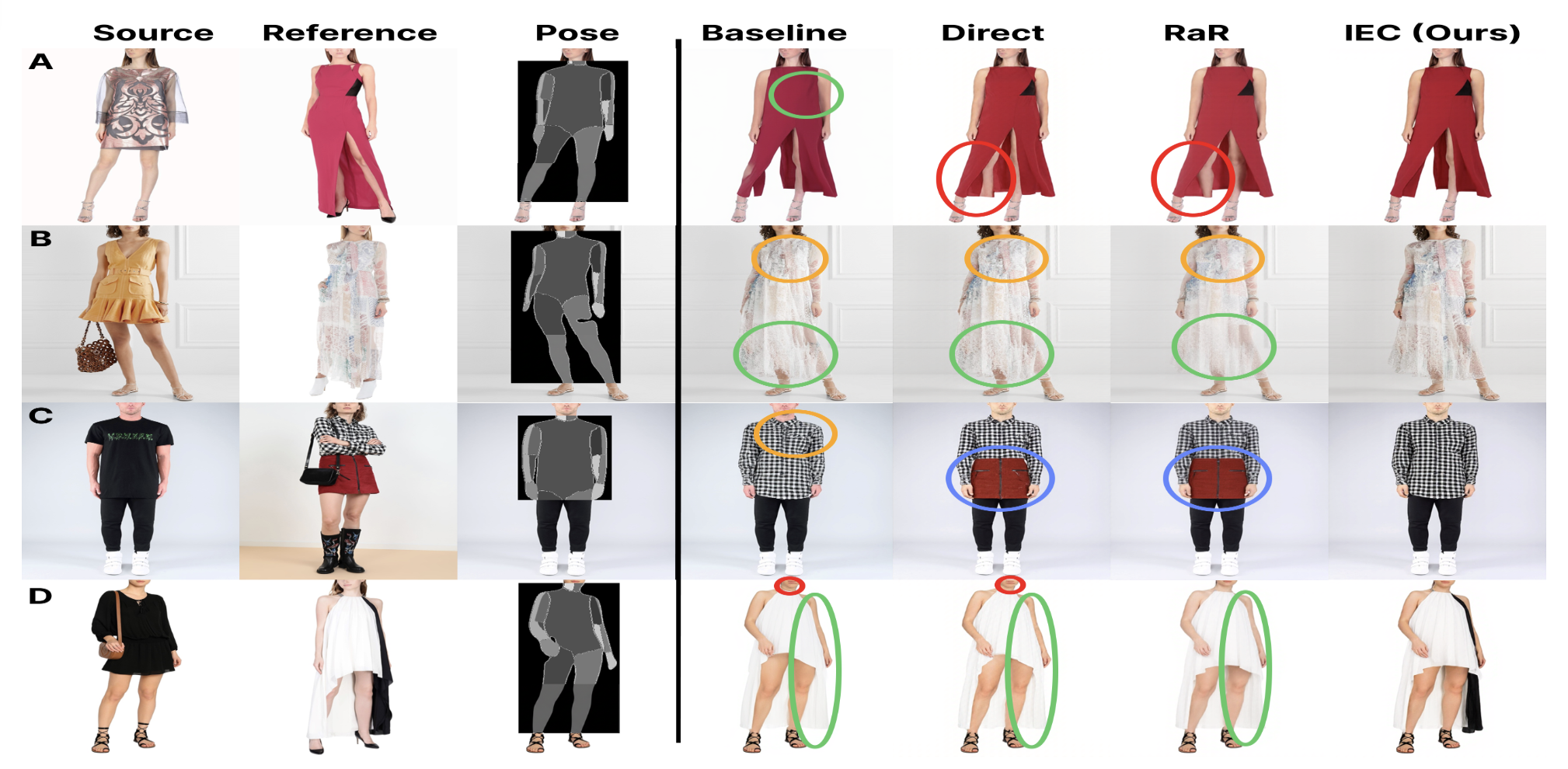
- Mar 2026 New preprint: When Rubrics Fail: Error Enumeration as Reward for Virtual Try-On
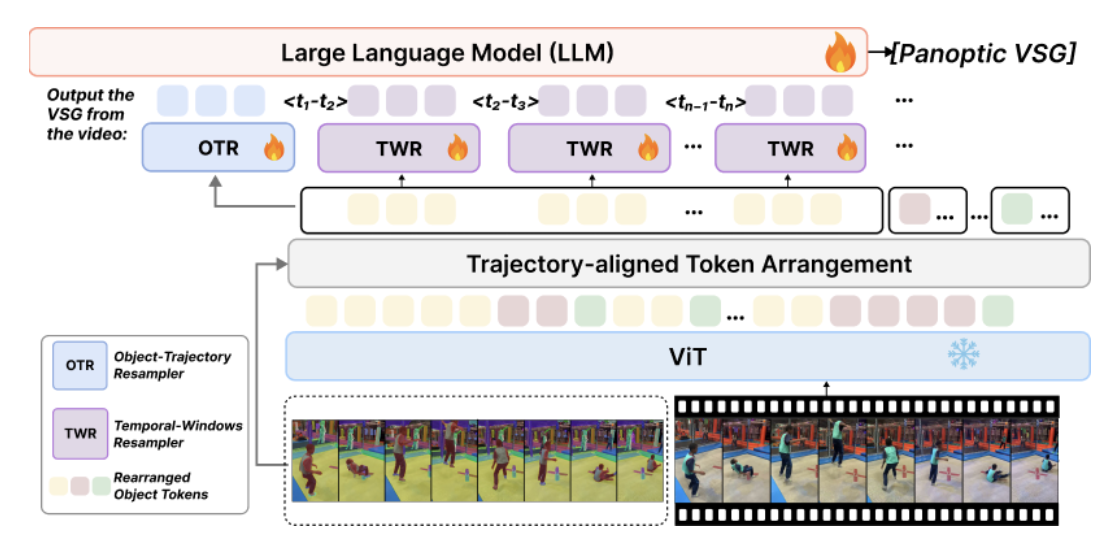
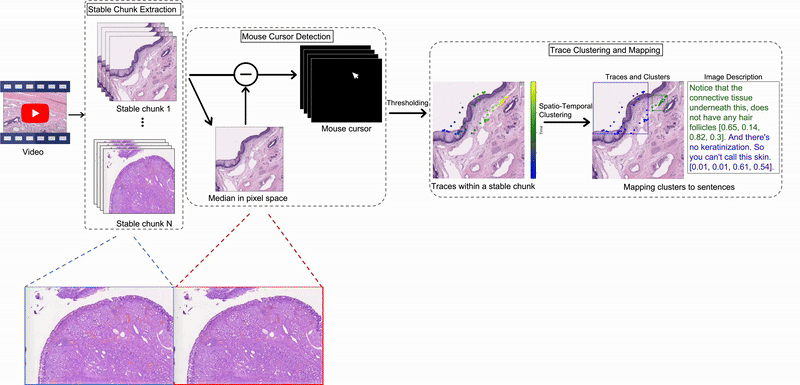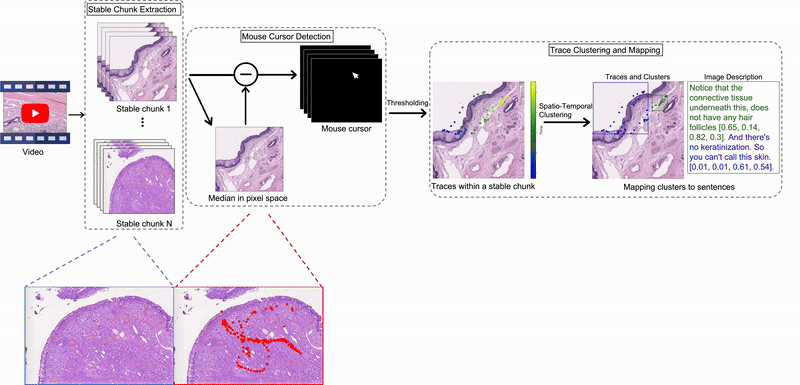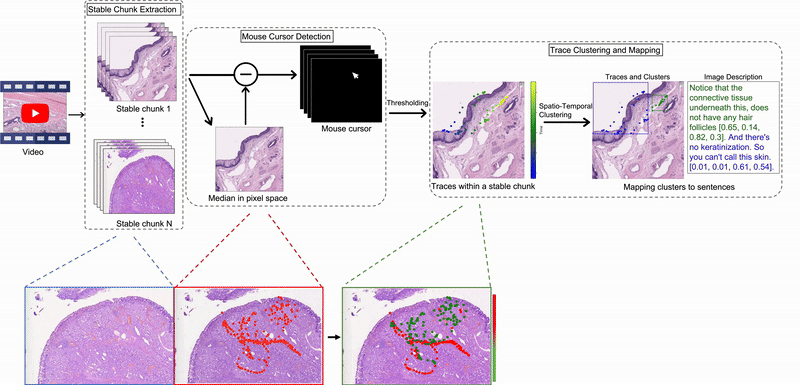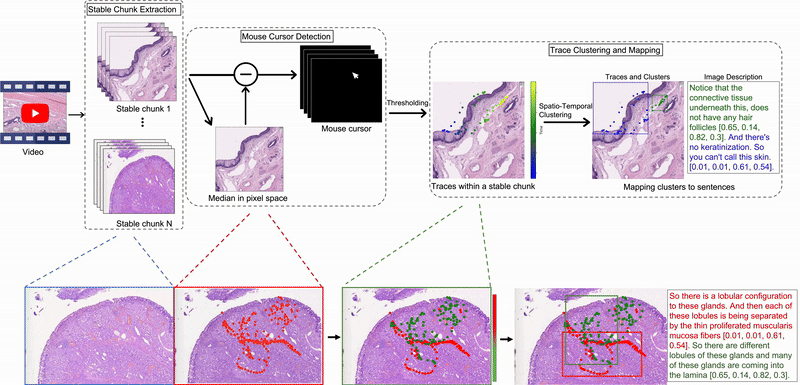
- Feb 2026 New preprint: Synthetic Visual Genome 2: Spatio-Temporal Scene Graphs from Videos
- Feb 2026 Joined AI2 PRIOR team as a student researcher
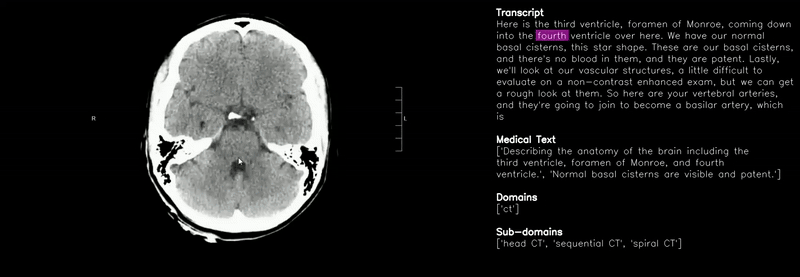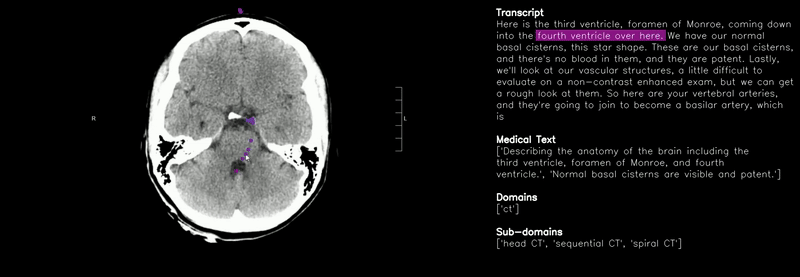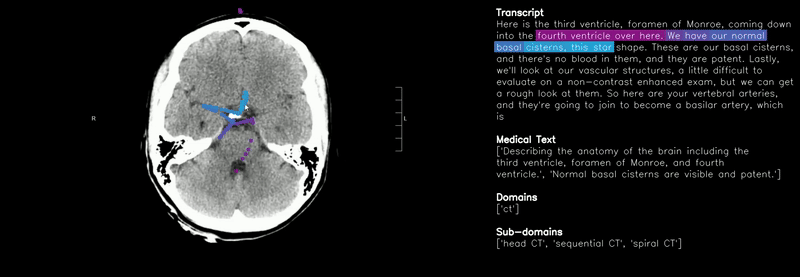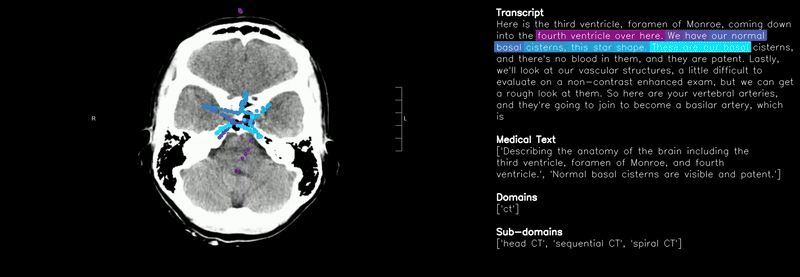
- 2025 MedicalNarratives accepted at NeurIPS 2025
- 2025 PathFinder accepted at ICCV 2025
- Jan 2026 Organizing the EvGenFM Workshop (Evaluation of Generative Foundation Models)
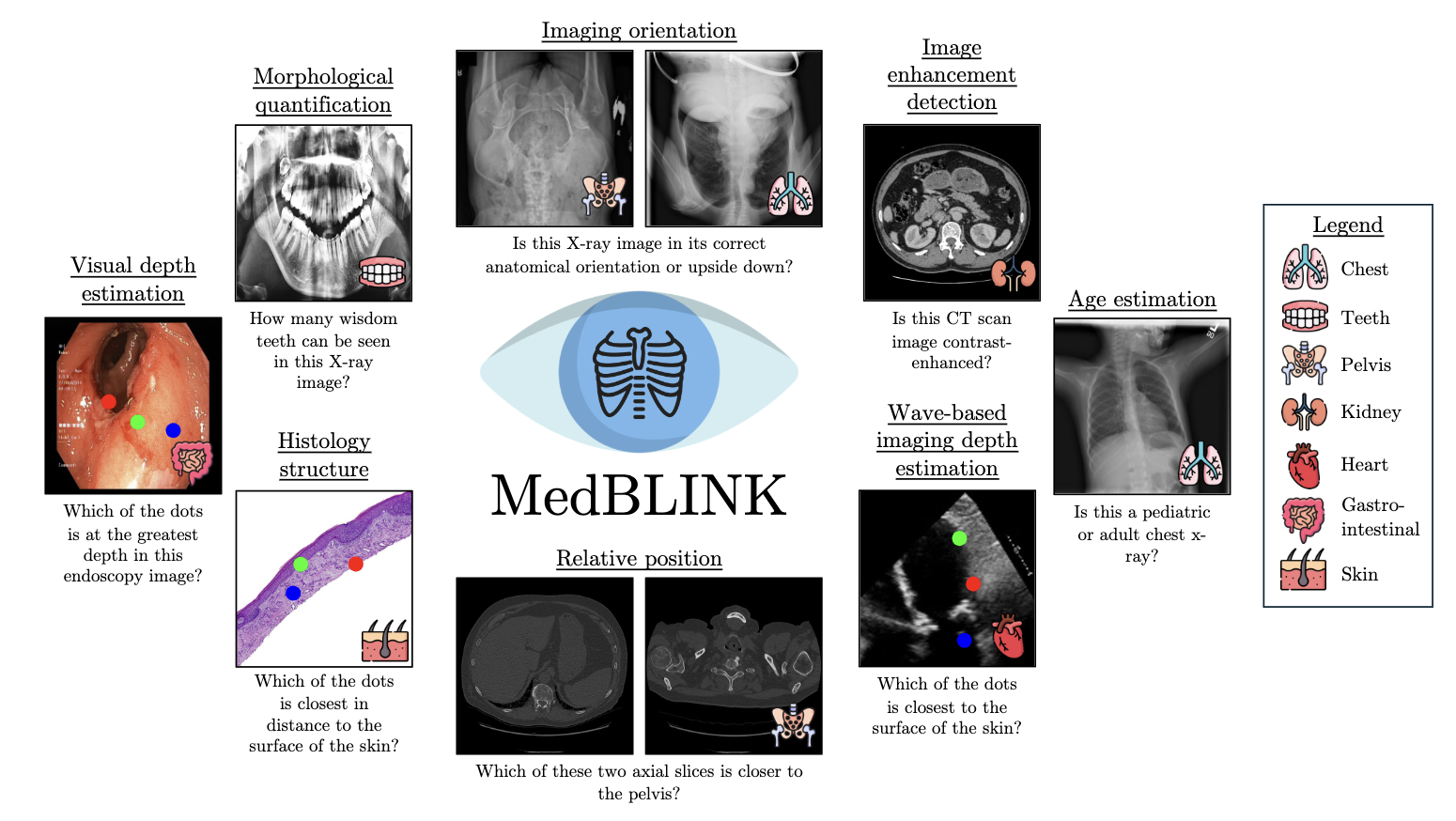
- 2025 MedBLINK accepted at CVAMD Workshop, ICCV 2025
- May 2025 Started PhD research internship at Amazon
- Jun 2024 UW Population Health Initiative — AI Pilot Research Grant Award
- Apr 2024 Started AIML research internship at Apple
- Feb 2024 Quilt-LLaVA accepted at CVPR 2024
- Oct 2023 Medical AI Renaissance accepted for Microsoft Accelerating Foundation Models Research Grant
- Sep 2023 Quilt-1M accepted at NeurIPS 2023 (Oral)
Experience
PhD Research Intern
AIML Research Intern
Graduate Research Intern
Student Researcher
Featured Talk
Quilt-1M & Quilt-LLaVA: Building Medical Vision-Language Models from YouTube
Invited talk at Cohere For AI on curating large-scale medical vision-language datasets from educational videos and training multimodal models for histopathology.
Publications

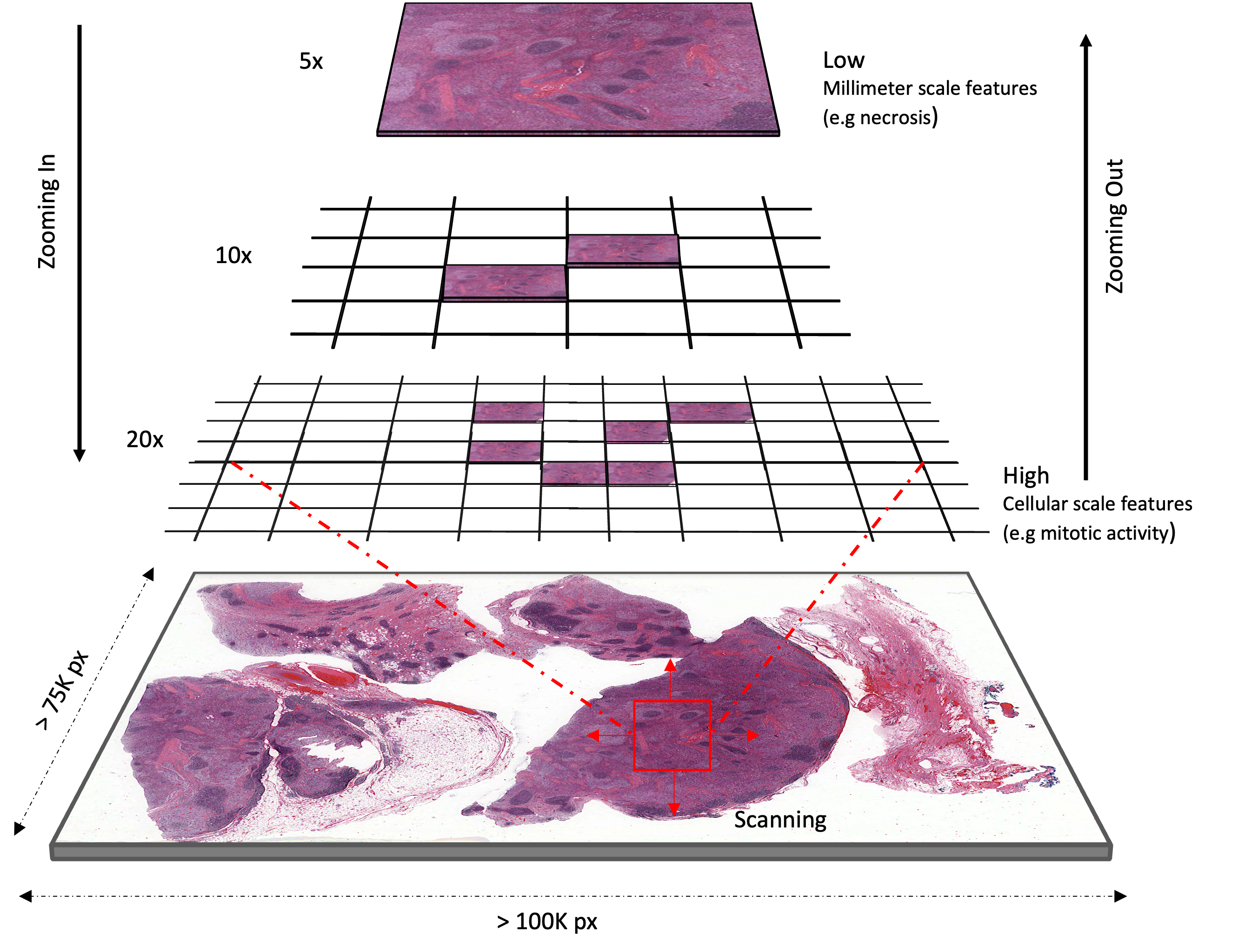
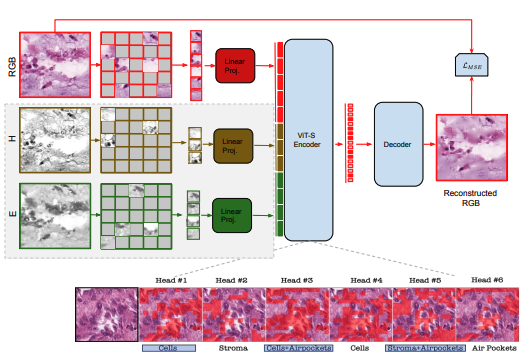

Teaching
- E E 562: Artificial Intelligence For Engineers — Winter 2026 Guest Lecturer
- CSE 455: Computer Vision — Autumn 2025 Teaching Assistant
- CSE 473: Introduction to Artificial Intelligence — Spring & Autumn 2023 Teaching Assistant
- CSE 160: Data Programming — Autumn 2022 & Winter 2023 Teaching Assistant
- EEE 203/201: Fundamentals of Electronic & Electrical Engineering — 2019 Teaching Assistant
Service & Mentoring
Workshop Organizing
- EvGenFM 2026 — Evaluation of Generative Foundation Models
Reviewing
- CVPR 2026
- NeurIPS 2025
- ICCV 2025
- ECCV 2026
- IEEE Transactions on Medical Imaging (TMI)
Mentoring
Awards
- UW Population Health Initiative — AI Pilot Research Grant (2024)
- Microsoft Accelerating Foundation Models Research Grant (2023)
People
Students I have mentored or am currently mentoring. See the full misc page for more details and ongoing projects.
Current Students
Kevin Zhang
Kevin Xiao
Alumni
Pavan Kumar Anand
Fatwir S. Mohammed
Tario G. You
Education
- University of Washington — Ph.D. in Computer Science & Engineering 2021 – 2026
- Obafemi Awolowo University — B.Sc. in Electronic & Electrical Engineering 2013 – 2019